记一次乱序漫画的拼接复原
前情提要
在某论坛摸鱼,发现有大佬发了一个很大的悬赏贴,要求是提取某漫画网站的原档。看完帖子,当时就很好奇这个网站到底有多难提取,于是就有了这篇文章。
悬赏帖内容
车轱辘话就不复制粘贴了,就提一些重要的信息~
首先帖子提供了几个原图,跟下面这个一样,都是切片并完全打乱顺序的。原图分辨率为1120x1560,这里只是一个WriteUp,所以只放出25%大小的版本,这样图片加载也快。

悬赏帖里还说,帖主已经问过好几个大佬,但是“提取的图片没法完美”。好吧,那咱们就来会一会这个网站。
前排提示:本文只是分享讨论思路,并不会有大段大段的代码给你抄。各位有能力的还是请多多支持正版,这样作者才有动力继续画下去,就跟《俺妹》那个卖同人志的黑猫一样。
观察网站
输入网址,点进去一看,就是一个正儿八经的正版漫画网站。虽然大部分是付费漫画,但是首页上也有不少写着「無料まんが」,所以不需要注册和付费就可以一探究竟。
乍一看,好像就是一个普通的阅读器,如下所示。

打开控制台看看能不能直接拿到图片,结果发现整个页面只有一个canvas,图片并没有直接写在html里头。
虽然没法在Inspector里头找到图片链接,但还是有其它办法的。毕竟这个网站能给用户显示这些漫画页面,那必然要从服务器加载这些对应资源,然后在浏览器显示。下面就来说一说我试过的一些方法。
PS拼图
这个。。。我当然是不会去尝试的,费时费力。如果只有一张图,当拼图玩还差不多;那么多张图等着复原,这个方法肯定直接抛弃。
当然,如果数量特别少,写通用处理代码又比较麻烦(或者不会编程),那直接人工处理下也未尝不可。
截图大法
首先,最简单的方法一定是截图了。当然,这里的截图并不是拿平时的截图工具来搞,而是用canvas自带的特性。
简单翻一下文档就发现有个东西叫toDataURL。
HTMLCanvasElement.toDataURL()
The HTMLCanvasElement.toDataURL() method returns a data URI containing a representation of the image in the format specified by the type parameter (defaults to PNG). The returned image is in a resolution of 96 dpi.
1 | canvas.toDataURL(type, encoderOptions); |
尝试了下,发现该网站似乎对这个API做了处理。正常的canvas是有这个API的,但是在漫画网站上面调用就会报错,提示“is not a function”。后来稍微研究了一下,就发现了下面这段代码。
1 | beforeMount: function () { |
一个比较简单的处理方法就是在Chrome的Source面板,通过加载本地修改过的文件来实现override。不过当时没想那么多,也就没试。
于是我回去翻了下那个悬赏帖,有坛友提出可以在控制台右键截图。我去试了下,发现还真可以。。。只要在Inspector中找到canvas,然后右键,选择“Screenshot Node”,就能拿到一张对应canvas的png图片。
这个方法基本上是以不变应万变了,只要能显示出来,就能对canvas截图保存。虽然保存的并不是真正的原图,但是清晰度什么的都没啥问题,自己用的话绰绰有余了。不过网站如果在上面加个水印啥的,就凉了。
对于这个截图大法,论坛有老哥写了个demo,用selenium来自动操作,也算是一个不错的方案。
获取原图
上面一直都是截图,也就是直接处理canvas内容后,重新拿到的图。如果要偷懒的话,那么任务已经完成。但悬赏帖的要求是原图,所以继续看看。
从上面的摸索就得知,图片链接没有放在html里头,所以这时候就点开Network面板,随便翻几页,果然就能看到一些请求,如下所示。
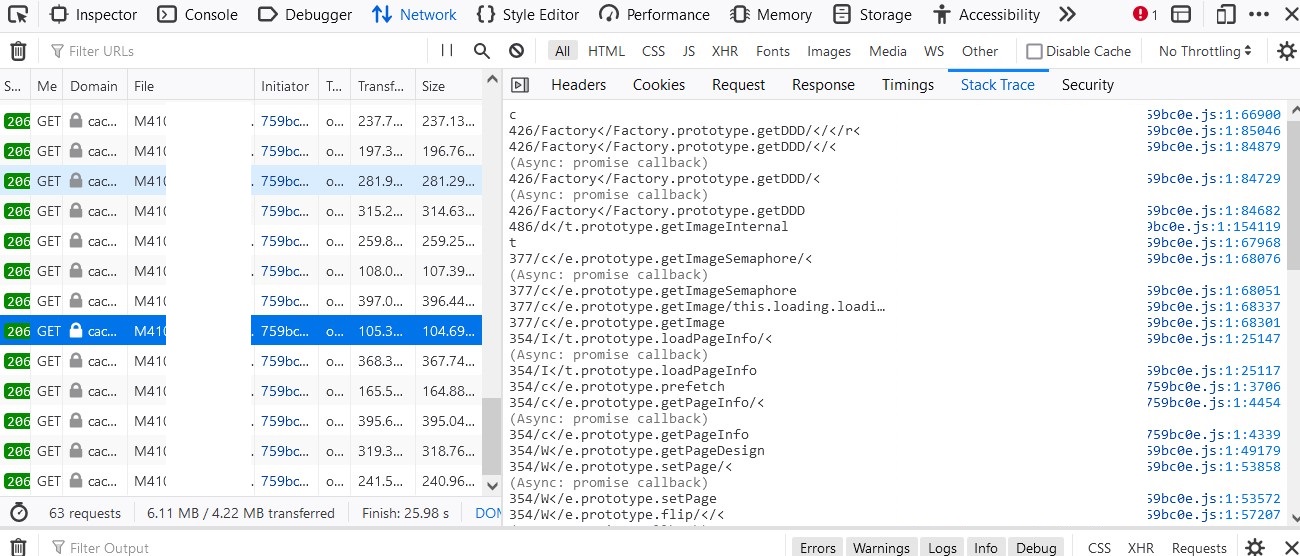
首先瞄一眼Response Payload,看看都返回了些啥。

好吧,看起来返回的内容已经被加密了。不过别急,这时候看看Stack trace,观察一下这个请求是从哪里发起的。毕竟再怎么加密,这个阅读器总得解密了才能展示给读者嘛。getImage这种名字,一看就很可疑对吧,那就点进去看看。
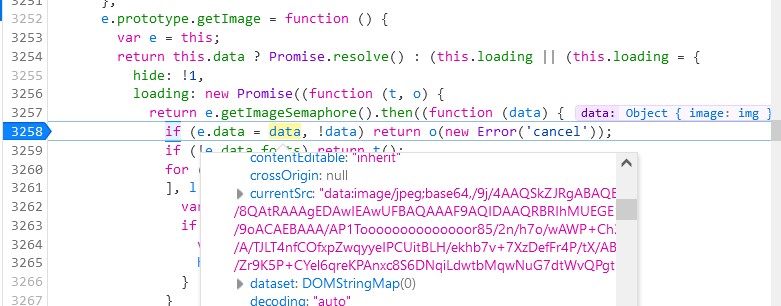
打几个断点,就已经看到图片资源了。不过这里图片是以base64形式存在的,所以只需要把那一大串东西复制到浏览器的地址栏,就可以显示出来了。当然,这么长的字符串,直接复制到地址栏会卡死,所以可以用window.open()来完成。
拼接原图
从这里开始,就很难逆向了,因为关键的逻辑全部被混淆了,完全看不明白。。。
打断点跟踪之后发现,混淆后的js在进行一些拼字的操作,有“ctx”,“canvas”等引人注目的单词。call stack如下所示。
1 | y |
不过就算到这一步也没什么用,关键的拼接逻辑我根本逆向不出来。当然,我比较菜,大佬们在这里应该会用AST(Abstract Syntax Tree,抽象语法树)来分析并还原代码。
所以我又回去翻那个悬赏帖,看看能不能收获点灵感。其中有一个层主写道:“记下每组draw位置”,一下子把我点醒了。我之前虽然回复过“在画上去之前截胡,把混淆/加密解密当黑盒”,但是我一直思考的是如何打断点拿到切图数据。实际上根本就不需要那么大费周章,只需我跟阅读器的绘制方式一样,不就能把原图给还原出来了么?所以问题也就转化成了如何截取这些drawcalls。
众所周知,调用drawImage就可以把一张现有的图片画到canvas上。
CanvasRenderingContext2D.drawImage()
The CanvasRenderingContext2D.drawImage() method of the Canvas 2D API provides different ways to draw an image onto the canvas.
1 | void ctx.drawImage(image, dx, dy); |
所以说,把这个drawImage函数override一下,就能看到这些drawcalls,并且还能拿到打乱顺序的原图。
1 | ctx.drawImage = function(img, x, y, copyW, copyH, px, py, copyW, copyH){ |
执行之后发现,每一页的drawcalls居然有几百条。。。不过没关系,反正位置数据已经到手,只要全部执行完,就能把图片复原。这里我选择用比较熟悉的Python来完整这项工作,其实就是用Python的Pillow库把drawImage重新实现一次,其实就两行。不过这些drawcalls里头有些无效的指令,直接执行是跑不通的,还需要提前过滤一次。
1 | def ctx_drawImage(sx, sy, sWidth, sHeight, dx, dy, dWidth, dHeight, in_img=in_img, out_img=out_img): |
下面是还原过程图,每一张图都代表了30个drawcalls,可以很直观的看到这里头有相当多的废指令,前100多个drawcalls基本就在乱拼。同时也可以发现,最后拼出来的图要比原图稍微小一点(用了灰底加以对比)。这么看来,最开始的那个乱序原图还塞了一些无效的信息进去。。。

到这里,总算是成功还原一张图了~
当然,这个距离完美的结果还差得远,比如批量操作什么的。而且思路本身其实也很简单,并没有什么技术含量在里面,不过对我来说还算是一次比较有意思的历程。至于方便快捷一站式解决方案,还是留给有能力的大佬去研究吧。
后记
话说回来,这么大规模的正版漫画网站,居然没有利用debugger来阻碍调试,也是有点奇怪了。甚至连米哈游的“米游社”网站,都知道要加入debugger,防止小白获取cookie并使用GitHub上面的原神自动签到项目。反复调用debugger我个人觉得还是挺烦的,这个keyword也没法让浏览器屏蔽掉,如果没有经验,还真不好绕过去。
这些年咱们的版权意识也在不断提高,如果版权方的服务水平也跟着不断上升,相信这类悬赏帖也会越来越少吧。反正我在steam买游戏是挺舒服的,下载更新一条龙服务,还有云存档,简直不要太方便。
最后,还是希望大家有能力的话多多支持正版吧,销量不行别人就不画了。。。