Stable Diffusion 部署运行笔记
最近AI技术发展得如火如荼,刚好我对图片生成挺感兴趣,就决定玩一下 Stable Diffusion,顺便记录一下过程。
至于为什么不用网上提供的图片生成服务呢?首先,这些服务基本都是付费的,而且每个月还有配额以防滥用。其次,网上的版本通常都有各种限制,想必不少人都见识过ChatGPT的经典名言:“As a large language model trained by OpenAI”。。。五花八门的限制和道德准则总让人觉得差点意思,所以说本地部署一个实例才是硬道理。
0x01 - 准备工具
Linux下部署
- 安装 WSL2(
wsl --install)- 如果不想用默认的 Ubuntu 可以看Install Linux on Windows with WSL
- 拥有一张 Nvidia 显卡并且安装了驱动
- 我用的是 RTX 3060 Laptop GPU(6GB VRAM)
- 根据CUDA on WSL User Guide,R495 及之后的驱动版本将支持 WSL2 的 CUDA,无需另外安装驱动
- Anaconda(可有可无,我没装)
注:Windows部署也很容易,只不过使用WSL2也很方便,而且哪天不想玩了可以直接删除,不会影响到Windows。
0x02 - SD部署
现在比较流行的是AUTOMATIC1111/stable-diffusion-webui这个懒人包,只需要跑一键脚本就可以完成安装。
1 | # 安装依赖 |
如果网速比较慢的话,一键脚本应该是要跑很久的,因为要安装依赖,以及下载 Stable Diffusion 默认的模型。
如果运行时出现 No module 'xformers'. Proceeding without it,可以直接无视。根据论坛帖子,最新版本在使用 Torch2,性能更高,因此N卡不再需要使用 xformers。
0x03 - txt2img入门
关于 Stable Diffusion 的原理,有一篇相当不错的入门文章How does Stable Diffusion work?,感兴趣可以看看。
模型可以在Civitai下载,初次体验建议挑选一些下载次数多的Checkpoint,比如BRA(Beautiful Realistic Asians) V5。LoRA是辅助类的模型,比如生成更好看的面部。Textual Inversion也是辅助的,比如生成黑丝。这两种模型不是必须,可以先不下载。
Stable Diffusion WebUI 的主要目录结构如下:
1 | ├── embeddings(存放Textual Inversion) |
启动之后,在浏览器中访问http://127.0.0.1:7860即可。
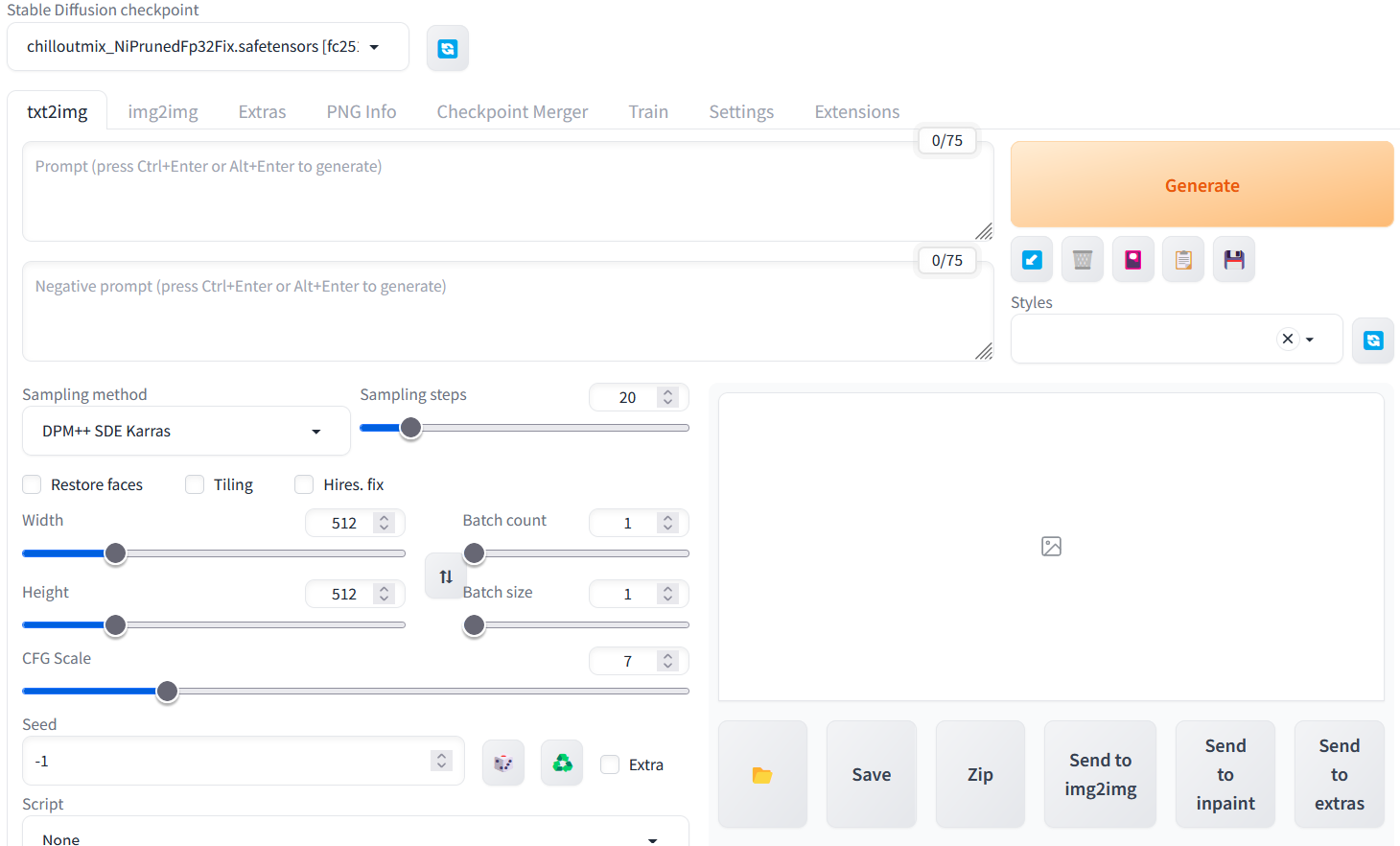
我们主要使用txt2img面板,通过一些提示词(prompt)来生成图片。当然,我知道没图你们是不会看的,所以先展示一下2023年5月的ai功力。这里使用的模型是ChilloutMix。虽然模型本身具有NSFW生成能力,但是生成SFW图片也是完全没有问题的。

好了,接下来稍微介绍一下各种参数,其实大部分在官方文档都有写,所以我只记录重点。
Stable Diffusion checkpoint
这个就是最重要的Checkpoint模型了。不得不说自带的v1-5-pruned-emaonly没什么用,强烈建议在Civitai找一些更符合自己口味的模型。Checkpoint模型不需要修改文件名,直接放进对应文件夹,然后点击右边的刷新图标,就能在下拉列表看到了。切换模型需要加载,等待时间大概十几秒,稍微耐心一点。
Prompt
这个可是重中之重,如果没有好的prompt,哪怕模型再好也生成不出好看的图片。prompt我也不太会写,基本都是抄大佬的。
一般有两种地方可以找到prompt:
- 各种整理好的文档(例如:CIVITAI法典)
- Civitai 的模型页面会展示一些高赞图片,部分作者有提供prompt
一个比较好的prompt看起来是这样的(修改自su943515688309的作品,去除了NSFW词条)
1 | (RAW photo, best quality), (realistic, photo-realistic:1.3), best quality, masterpiece, an extremely delicate and beautiful, extremely detailed, CG, unity, 2k wallpaper, Amazing, finely detail, masterpiece, light smile, best quality, extremely detailed CG unity 8k wallpaper, huge filesize, ultra-detailed, highres, extremely detailed, 1girl, maid, (swimming pool:1.2), kawaii bikini, (spread legs), hair ornament, looking at looking at viewer, small breasts, <lora:japaneseDollLikeness_v10:0.2>, <lora:koreanDollLikeness_v15:0.2>, <lora:cuteGirlMix4_v10:0.4>, <lora:chilloutmixss30_v30:0.2> |
先来说说()和[]的用法:
- (word) - 加权(1.1)
- ((word)) - 加权(1.1*1.1=1.21)
- [word] - 降权(1/1.1=0.909)
- (word:1.5) - 加权(1.5)
- (word:0.25) - 加权(0.25),实际上等同于降权4倍
()和[]都可以用\来 escape
注:{}是 NovelAI 的用法,等价于加权(1.05)
<>表明使用的LoRA模型:
- 格式为
<lora:filename:multiplier>- 例如
<lora:cuteGirlMix4_v10:0.4>
- 例如
multiplier代表效力强度,范围是0 - 1- 默认是1(最大效力)
- 0等同于关闭
filename必须跟文件名一模一样(不带后缀名)- 例如调用
cuteGirlMix4_v10,那么Lora文件夹必须要有cuteGirlMix4_v10.safetensors,否则调用无效
- 例如调用
这里没有用到Textual Inversion,不过使用方法也很简单,直接写文件名就行,例如pureerosface_v1。这个当然也是可以加权的,例如(pureerosface_v1:0.8)。
Hypernetworks我没用过,模型很少而且没什么人下载,这里不做介绍。
Negative Prompt
Negative Prompt 是你的魔法护盾,用来消除不想出现的东西。这个感觉都大同小异,一般直接复制粘贴即可。
1 | bra, covered nipples, underwear, EasyNegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans, extra fingers, fewer fingers, ((watermark:2)), (white letters:1), (multi nipples), lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low qualitynormal quality, jpeg artifacts, signature, watermark, username, bad feet, {Multiple people}, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worstquality, low quality, normal quality, jpegartifacts, signature, watermark, blurry, bad feet, cropped, poorly drawn hands, poorly drawn face, mutation, deformed, worst quality, low quality, normal quality, jpeg artifacts, signature, extra fingers, fewer digits, extra limbs, extra arms, extra legs, malformed limbs, fused fingers, too many fingers, long neck, cross-eyed, mutated hands, polar lowres, bad body, bad proportions, gross proportions, text, error, missing fingers, missing arms, extra arms, missing legs, wrong feet bottom render, extra digit, abdominal stretch, glans, pants, briefs, knickers, kecks, thong, {{fused fingers}}, {{bad body}}, ((long hair)) |
这里的EasyNegative是Textual Inversion,抄大佬prompt却无法复刻结果的时候,要留意这种地方。如果你没有这个模型,生成结果肯定不一样的。而且最玄学的是,在没有模型的情况下,EasyNegative这个词条保留与否,又会得到不同的结果。
Style
可以把上面的 Prompt 和 Negative Prompt 保存成一个 preset,这样以后调用这种风格就可以直接选择,然后可以额外输入你想使用的prompt。
Sampling method
采样方法我看很多大佬用的都是DPM++ SDE Karras,我试了下效果确实不错。不同采样方法的对比图可以在官方文档查看,每个采样方法的具体原理可以看Stable Diffusion Samplers: A Comprehensive Guide,这里简单摘抄一部分。
- ODE solvers(常微分方程)
- Ancestral samplers
- 所有带
a的(Euler a,DPM2 a,DPM++ 2S a,DPM2 a Karras,DPM++ 2S a Karras) - 在每个采样步骤中向图像添加噪声
- stochastic(生成的图片不收敛)
- 所有带
- Karras noise schedule
- 所有带
Karras的 - 可以改进图片质量
- 所有带
- DPM and DPM++ (2022)
- UniPC (2023)
- UniPC (Unified Predictor-Corrector)
- 在低步数(5-10)有更好的表现
- Outdated
至于哪个表现更好,就见仁见智了。
下面是steps=20时,所有模型的表现:

下面是steps=50时,所有模型的表现:

所以,大体上可以用这两个sampler:
- 收敛:DPM++ 2M Karras
- 发散:DPM++ SDE Karras
Sampling steps
我这里跑了1 - 90的效果图,可以发现采样步数设置在20 - 25就可以了,再多也不会有大的改进。

Width & Height
默认是512x512,不过如果想生成一些竖屏图片,可以修改成512x768。图片尺寸太大的话,对应的生成时间也会长很多。但是注意,小尺寸和大尺寸生成出来的图片内容是完全不一样的!

可以看到,768x768生成的结果跟512x512的生成结果完全没关系,如果单纯想要放大图片,需要用其它特别的手段,例如Hires.fix。
CFG Scale
CFG Scale 代表输出跟输入的相似程度,这个是Classifier-free guidance。如果 CFG Scale 比较大,则将更符合 prompt,但可能会变形。如果 CFG Scale 比较小,则有可能偏离 prompt,但输出质量会更好。

可以看到从CFG=12开始,画面逐渐变得支离破碎。总而言之,CFG Scale 就是以 prompt 准确度换生成质量,一般设置在7 - 11即可。
Batch Count & Size
Batch Count:生成多少批次的图片
- 可以修改
ui-config.json来解锁更高的上限("txt2img/Batch count/maximum": 100)
Batch Size:每一个批次有多少图片
- 太多的话会爆显存,量力而行
下面是同样生成4张图片的时间对比:
1 | # Source: https://www.reddit.com/r/StableDiffusion/comments/wzsp8w/whats_the_actual_difference_between_batch_count/ |
Seed
种子默认是-1(随机),如果想复刻大佬的结果,必须要提供一模一样的数值。

可以看到不同种子生成出的结果差了十万八千里。
Script
脚本,这篇文章中的对比图都是用X/Y/Z Plot生成的,可以对比不同参数的效果,一目了然。
Generate
这个就不用多说了,就是生成。
这里附带其它的参数,有兴趣的读者可以尝试复刻一下。需要注意的是,虽然prompt提到了EasyNegative,但是我没有下载这个模型。如果你下载了,生成结果会不一样。
1 | Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2668558297, Size: 512x768, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix |
注:如果关闭了网页,再次打开时,所有参数都会恢复到默认值。Generate按钮旁边有一个↙️按钮,点击即可读取上一次的参数。
0x04 - txt2img进阶
Hires.fix
虽然生成的图片挺不错,但是512x768实在不够看,稍微放大看看就能发现细节比较糊,这时候就需要使用Hires.fix来放大图片了。
勾选Hires.fix之后会出现下面这些参数
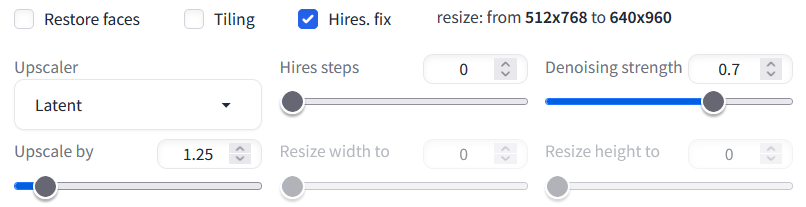
Upscaler基本上只能选择Latent,因为其它会爆显存。。。
Upscale by 就是放大的倍数,这个很吃显存,我一般设置成2,更高的数值会爆显存。其实个人感觉1024x1536也已经很够用了,当然如果看到喜欢的,又有高端显卡,那肯定分辨率越高越好啦。
Denoising Strength 是一个很有意思的参数,范围在0 - 1之间,太低画面会糊,太高画面会变。所以这个只能自己慢慢调试了,感觉一般设置成0.4 - 0.5会比较好。我用X/Y/Z Plot制作了一个对比图,倍数2x,跑了半个小时。。。

原图接近20MB,虽然这里展示的是压缩再压缩的版本,但还是能发现0.4是最后一个忠实于原作的图。从0.5开始就篡改原图了,数值越高就越离谱,0.7甚至多了两只手。从0.7往后的背景天马行空,完全没法看。
注:放大倍数也会影响生成的内容,比如1.25x和2x的成品就完全不一样。
0x0? - 未完待续
写了这么多,却只是 Stable Diffusion 的冰山一角,还有很多功能我也没玩,等摸索之后再更新。
部分对比图还没制作,准备摸鱼的时候跑一跑