我对Python的理解是建立在实战上的,并没有正儿八经的去跟教程学过,因此决定参考各大教程查缺补漏。本计划鸽了一年,现在重新捡起来继续看。本文收集的都是一些相对不常用 / 不熟悉的东西,准备当速查手册翻看。
ord()获取字符的整数编码chr()把编码转成字符b''表示bytesencode()和decode(),编码和解码,参数是字符编码(如'utf-8')
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 >>> ord ("ABC" )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> TypeError: ord () expected a character, but string of length 3 found >>> ord ("A" )65 >>> ord ("字" )23383 >>> chr (23383 )'字' >>> '字符串' .encode('utf-8' )b'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2' >>> len (b'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2' )9 >>> u'字符串' .encode('unicode-escape' )b'\\u5b57\\u7b26\\u4e32' >>> len ('\u5b57\u7b26\u4e32' )3 >>> '\u5b57\u7b26\u4e32' '字符串'
Python3.6引入了f-string,可以直接对花括号内eval,用起来特舒服。如果是写新项目的话,%和format可以扔了。
用法:f'{}'
1 2 3 4 5 6 7 print (f"a * b = {a * b} " )print (f"val = {res['val' ]} " )print (f"result = {min (a, b)} " )print ( f"a = {a} \n" f"b = {b} " )
当然,还有一些比较冷门的玩法。
1 2 3 >>> a = 3.14159265 >>> print (f"{a:.4 f} " )3.1416
1 2 for x in range (1 , 4 ): print (f"{x:02} {x**2 :3 } {x**3 :4 } " )
特别注意这里{x:02}代表宽度为2,不足就在前面补0,最后输出如下:
Python默认输出是左对齐的,可以使用>改为右对齐
1 2 3 4 5 6 7 s1 = 'a' s2 = 'ab' s3 = 'abc' print (f'{s1:>5 } ' )print (f'{s2:>5 } ' )print (f'{s3:>5 } ' )
这里输出宽度是10,结果如下(@代表空格):
1 2 3 4 5 6 7 8 9 10 >>> a = 123 >>> print (f"{a:x} " )7b >>> print (f"{a:o} " )173 >>> print (f"{a:e} " )1.230000e+02
1 2 3 4 5 6 7 8 9 10 11 class Color : def __init__ (self, name, color_code ): self .name = name self .color_code = color_code def __repr__ (self ): return f"{self.name} --> {self.color_code} " color = Color('Azure' , '#007fff' ) print (f'{color} ' )
运行上面程序,我们会得到Azure --> #007fff
1 2 3 4 5 6 7 >>> import decimal>>> width = 10 >>> precision = 4 >>> value = decimal.Decimal("12.34567" )>>> f"result: {value:{width} .{precision} }" 'result: 12.35'
区别:list可变,tuple不可变
append(sth)在末尾追加元素insert(idx, sth)把元素插入到指定位置pop(idx)删除指定位置元素,不传参则删除末尾元素
定义一个元素的tuple有坑!
t = (1)是直接当成数学表达式计算t = (1, )才是正确的做法
dict和set是用哈希表实现的,说实话,我写了好几年Python,好像还真没怎么用过set。
从Python3.6开始,字典有序!
两种方法可以获取value:
d[key]d.get(key, default_val)
失败就会返回default_val
不传入default_val就会返回None
1 2 3 4 5 6 7 >>> d = {"key" :"value" }>>> d["key" ]'value' >>> d.get("key" ,"nothing_here" )'value' >>> d.get("key2" ,"nothing_here" )'nothing_here'
集合内元素不能重复,传入重复元素会被自动过滤掉
创建set需要提供一个list,例如:s = set([1, 2, 3])
add(key)添加元素remove(key)删除元素&取交集(intersection)|取并集(Union)
默认参数必须指向不变对象(例如None),否则会翻车,如下所示:
1 2 3 4 5 6 7 8 def lst_append (lst=[] ): lst.append('args' ) return lst >>> lst_append()['args' ] >>> lst_append()['args' , 'args' ]
*args可以接收任意数量的参数
如果已经有list或者tuple,可以直接转换成可变参数传入
1 2 3 4 5 6 7 8 9 def func (*args ): print (args) lst = [1 , 2 , 3 ] >>> func(*lst)(1 , 2 , 3 ) >>> func(lst)([1 , 2 , 3 ],)
**kwargs可以接收任意数量的键值对
1 2 3 4 5 6 def func (**kwargs ): print (kwargs) >>> func(type ="apple" , amount="5" ){type : "apple" , amount: "5" }
引入版本:Python 3.8(PEP 570 -- Python Positional-Only Parameters )
限定位置参数和其它参数之间用/分隔开。函数调用的时候,无法通过关键字形式传递限定位置参数。限定位置参数可以用在一些不需要强调关键字的地方,比如下面的例子,x并没有什么特殊的含义,所以只接受直接传参没问题。
1 2 3 4 5 6 7 8 9 def add (x, / ): print (x + 1 ) >>> add(5 )6 >>> add(x=5 )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> TypeError: add() got some positional-only arguments passed as keyword arguments: 'x'
命名关键字参数用来限制关键字参数的名字
命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数
1 2 def person (name, age, *, city, job ): print (name, age, city, job)
注意:调用时跟位置参数(positional argument)不同,这里必须要传入参数名
1 person('Jack' , 24 , city='Beijing' , job='Engineer' )
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*
1 2 def person (name, age, *args, city, job ): print (name, age, args, city, job)
命名关键字参数可以有默认值
1 2 def person (name, age, *, city='Beijing' , job ): print (name, age, city, job)
一个比较著名的问题就是汉诺塔 (Hanoi)。最早接触这个问题是在初中,当时用C语言解决的,也是用的递归法。但是当时只是依葫芦画瓢写出来,并没有理解为什么这么写。刚刚写了一次也没写出正确解法,不过比较接近,看来还是不理解,只好老老实实去搜汉诺塔的解析。
算法关键步骤如下:
把n-1个盘子由A移到B
把第n个盘子(最下面,最大的那个盘子)由A移到C
把n-1个盘子由B移到C
以上三个步骤,对应的就是下面三个操作
1 2 3 move(n - 1 , a, c, b) move(1 , a, b, c) move(n - 1 , b, a, c)
如果只剩下一个盘子的话,那当然就是直接从A移到C。
所以最后的题解如下:
1 2 3 4 5 6 7 8 9 def move (self, n, a, b, c ): if n == 1 : print (a, "-->" , c) else : move(n - 1 , a, c, b) move(1 , a, b, c) move(n - 1 , b, a, c) move(10 , 'A' , 'B' , 'C' )
参考文章:汉诺塔的图解递归算法
[start : stop : increment]
list,tuple,str都可以进行切片
s[:1]取第一个元素s[-1:]取最后一个元素如果使用s[0]或者s[-1]就有可能出现越界报错(例:空字符串)
for循环可以用在可迭代对象上
dict的for循环:
默认情况下,迭代的是key
迭代value,用for value in d.values()
同时迭代key和value,用for k, v in d.items()
判断是否为可迭代对象
1 2 3 >>> from collections import Iterable>>> isinstance ('abc' , Iterable)True
格式:expr for ... in ...
1 2 >>> [x * x for x in range (1 , 11 )][1 , 4 , 9 , 16 , 25 , 36 , 49 , 64 , 81 , 100 ]
列表生成式可以使用if...else
1 2 3 4 5 6 >>> [x for x in range (1 , 11 ) if x % 2 == 0 ][2 , 4 , 6 , 8 , 10 ] >>> [x if x % 2 == 0 else -x for x in range (1 , 11 )][-1 , 2 , -3 , 4 , -5 , 6 , -7 , 8 , -9 , 10 ]
把列表生成式的[]改成()
1 2 3 >>> g = (x * x for x in range (10 ))>>> g<generator object <genexpr> at 0x1022ef630 >
函数定义中包含yield,那么该函数就是generator
generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行
用for循环调用generator时,捕获StopIteration错误来获取返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def sq (n ): x = 0 while x < n: x += 1 yield x * x >>> g = sq(3 )>>> next (g)1 >>> next (g)4 >>> next (g)9 >>> next (g)Traceback (most recent call last): File "<stdin>" , line 1 , in <module> StopIteration for i in sq(3 ): print (i)
Iterable(可用for循环)
list
dict
str
Iterator(惰性可用next迭代)
Iterator是Iterable的子集。把list、dict、str等Iterable变成Iterator可以使用iter()函数。
1 2 3 4 5 6 7 8 9 num = [1 , 2 , 3 ] num_iter = iter (num) >>> num_iter<list_iterator object at 0x000001C41783FF40 > >>> next (num_iter)1 >>> next (num_iter)2
1 2 3 4 5 6 def add (x, y, f ): return f(x) + f(y) >>> add(-5 , 6 , abs )11
map(func, iterable)
1 2 3 4 5 6 def f (x ): return x * x >>> r = map (f, [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ])>>> list (r)[1 , 4 , 9 , 16 , 25 , 36 , 49 , 64 , 81 ]
reduce(func, iterable)
效果:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
1 2 3 4 5 6 7 8 9 10 from functools import reducedef add (x, y ): return x + y >>> reduce(add, [1 , 3 , 5 , 7 , 9 ])25
filter(func, iterable) -> iterator
filter()把传入的函数依次作用于每个元素,然后根据返回值,True保留元素,False丢弃元素。注意filter()返回的是一个filter对象,并且由于是iterator,序列只能输出一次。
1 2 3 4 5 6 7 8 9 lst = [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ] def find_odd (x ): return x % 2 >>> lst_2 = filter (find_odd, lst)>>> lst_2<filter object at 0x000001C41783FC10 > >>> [x for x in lst_2][1 , 3 , 5 , 7 , 9 ]
sorted(iterable, key=func, reverse=bool)
key指定的函数将作用于iterable的每一个元素上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 lst_1 = [2 , 11 , -4 , -9 , 3 ] >>> sorted (lst_1)[-9 , -4 , 2 , 3 , 11 ] >>> sorted (lst_1, key=abs )[2 , 3 , -4 , -9 , 11 ] >>> sorted (lst_1, key=abs , reverse=True )[11 , -9 , -4 , 3 , 2 ] lst_2 = ['cherry' , 'apple' , 'Banana' ] >>> sorted (lst_2)['Banana' , 'apple' , 'cherry' ] >>> sorted (lst_2, key=str .upper)['apple' , 'Banana' , 'cherry' ]
如果不需要马上运算,可以把函数作为结果值返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def factorial (n ): def mul (): res = 1 for i in range (1 , n + 1 ): res *= i return res return mul >>> f = factorial(6 )>>> f<function factorial.<locals >.mul at 0x00000211F7A23280 > >>> f()720
lambda args: expr
1 2 3 4 5 f = lambda x: x * x def f (x ): return x * x
匿名函数只能有一个表达式,不用写return,返回值就是该表达式的结果
装饰器接受一个函数作为参数,添加一些功能,并返回一个函数
下面就是一个最简单的装饰器:
1 2 3 4 5 def decorator_func (original_func ): def wrapper_func (): print ("decorator_func exec!" ) return original_func() return wrapper_func
下面是两种等效的使用装饰器的方法:
1 2 3 4 5 6 7 8 9 10 11 12 def display (): print ("display exec!" ) decorated_display = decorator_func(display) decorated_display() @decorator_func def display (): print ("display exec!" )
执行结果如下:
1 2 decorator_func exec! display exec!
如果传入装饰器的函数带有参数,那么上面的装饰器就会报错,因为wrapper_func在定义时没有接受任何位置参数(positional argument)。所以,前面给出的装饰器应该这么写:
1 2 3 4 5 def decorator_func (original_func ): def wrapper_func (*args, **kwargs ): print ("decorator_func exec!" ) return original_func(*args, **kwargs) return wrapper_func
装饰器也可以是一个类
1 2 3 4 5 6 7 8 9 10 class decorator_class (object ): def __init__ (self, original_func ): self .original_func = original_func def __call__ (self, *args, **kwargs ): print ("decorator_class exec!" ) return self .original_func(*args, **kwargs) @decorator_class def display (): print ("display exec!" )
装饰器可以叠加使用。叠加使用时,先调用下面的装饰器。
1 2 3 4 @decorator_A @decorator_B def display (): print ("display exec!" )
上面这个等价于display = decorator_A(decorator_B(display))
但是这样并不会保留原函数的信息,例如display.__name__会变成wrapper而不是我们期望的display。
所以可以通过引入functools中的wraps来解决这个问题,对装饰器中的wrapper_func使用wraps并传入original_func
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from functools import wrapsdef decorator_A (original_func ): @wraps(original_func ) def wrapper_func (*args, **kwargs ): print (f"decorator_A exec! original_func = {original_func.__name__} " ) return original_func(*args, **kwargs) return wrapper_func def decorator_B (original_func ): @wraps(original_func ) def wrapper_func (*args, **kwargs ): print (f"decorator_B exec! original_func = {original_func.__name__} " ) return original_func(*args, **kwargs) return wrapper_func @decorator_A @decorator_B def display (): print ("display exec!" )
结果如下:
1 2 3 decorator_A exec! original_func = display decorator_B exec! original_func = display display exec!
如果如果不用wraps,结果如下:
1 2 3 decorator_A exec! original_func = wrapper_func decorator_B exec! original_func = display display exec!
这里抄一个装饰器的实际应用(测量运行时间):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import timedef timer (func ): def wrapper (): before = time.time() func() print ("Function took:" , time.time() - before, "seconds" ) return wrapper @timer def run (): time.sleep(2 ) run()
参考:
functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数
1 2 3 4 5 6 7 8 from functools import partialdef vol (x, y, z ): return x * y * z >>> vol_5 = partial(vol, 5 , 5 )>>> vol_5(10 ) 250
OOP以前看着也是一头雾水,后来还是在君浪大佬的指引下练会的。不过再看教程 ,我发现原来我还是不会OOP,很多高级点的特性完全不熟悉或者不了解。。。
__varName
这样就不能直接通过instance.__varName访问,但是本质只是解释器把变量名字改成了instance._className__varName
1 2 3 4 5 6 7 8 9 10 11 12 13 class Student (): def __init__ (self ): self .__gender = "Male" s = Student() >>> s.__genderTraceback (most recent call last): File "<stdin>" , line 1 , in <module> AttributeError: 'Student' object has no attribute '__gender' >>> s._Student__gender 'Male'
dir(obj)可以获得一个对象的所有属性和方法
getattr(obj, attr)、setattr(obj, attr, val)、hasattr(obj, attr)可以操作对象的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Student (): def __init__ (self ): self .__gender = "Male" s = Student() >>> dir (s)['_Student__gender' , '__class__' , ......] >>> getattr (s, '__class__' ) <class '__main__.Student' > >>> setattr (s, '__class2__' , 'Hello' )>>> getattr (s, '__class2__' )'Hello' >>> hasattr (s, 'haha' )False
类属性(class attr)跟实例(instance attr)不一样。
类属性可以当作是属性的默认值。所有实例可以访问类属性,而且同名的实例属性的优先级比类属性高。
访问方法:className.attr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Student (): gender = "N/A" s = Student() >>> Student.gender'N/A' >>> s.gender'N/A' >>> s.gender = "Male" >>> s.gender'Male' >>> del s.gender>>> s.gender'N/A'
1 2 3 4 5 6 7 8 9 def newMethod (self ): pass from types import MethodTypeinstance.newMethod = MethodType(newMethod, instance) ClassName.newMethod = newMethod
@property是Python内置的装饰器,可以把方法的调用变成属性的调用。
@property用来装饰getter方法,setter方法是可选的,不定义那就是只读属性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Rect (): @property def length (self ): return self .__length @length.setter def length (self, val ): self .__length = val @property def width (self ): return self .__width @length.setter def width (self, val ): self .__width = val @property def area (self ): return self .__length * __width f = Rect() >>> f.length = 2 >>> f.length2 >>> f.width = 5 >>> f.area = 100 Traceback (most recent call last): File "<stdin>" , line 1 , in <module> AttributeError: can't set attribute >>> f.area 10
class childClass(parentClassA, parentClassB)
通过多重继承,子类会拥有多个父类的所有功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class CPU (): cpu = "i5-10400F" class GPU (): gpu = "GTX 1660S" class Computer (CPU, GPU): pass f = Computer() >>> f.cpu'i5-10400F' >>> f.gpu'GTX 1660S'
__slots__用来限制该class的实例能添加的属性,试图绑定白名单外的的属性会得到AttributeError的错误
__slots__定义的属性仅对当前类的实例起作用,对继承的子类不起作用。除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__
1 2 3 4 5 6 7 8 9 10 class Student (): __slots__ = ('gender' ) s = Student() >>> s.gender = "Male" >>> s.age = 30 Traceback (most recent call last): File "<stdin>" , line 1 , in <module> AttributeError: 'Student' object has no attribute 'age'
__str__就是调用print()打印出来的信息,__repr__则是直接显示变量所打印出来的信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class CPU (): def __init__ (self ): self .cpu = "i5-10400F" def __str__ (self ): return f"This is CPU {self.cpu} " def __repr__ (self ): return f"This is CPU {self.cpu} . What do you expect?" f = CPU() >>> print (f)This is CPU i5-10400F >>> fThis is CPU i5-10400F. What do you expect?
如果一个类想被用于for...in循环,类似list或tuple那样,就必须实现一个__iter__()方法,然后,Python的for循环就会不断调用该迭代对象的__next__()方法拿到循环的下一个值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Add (): def __init__ (self ): self .cnt = 1 self .val = 0 def __iter__ (self ): return self def __next__ (self ): self .val += self .cnt self .cnt += 1 if self .val > 40 : raise StopIteration() return self .val >>> print ([i for i in Add()])[1 , 3 , 6 , 10 , 15 , 21 , 28 , 36 ]
要表现得像list那样按照下标取出元素,需要实现__getitem__()方法。如果需要处理slice,也是在getitem内部实现对应逻辑。
1 2 3 4 5 6 7 8 9 10 class Add (): def __getitem__ (self, n ): n += 1 val = 0 for i in range (n): val += i return val >>> f[5 ]15
当调用不存在的属性时,Python解释器会试图调用__getattr__(self, attr)来尝试获得属性。
1 2 3 4 5 6 7 8 9 10 11 class Student (): def __init__ (self ): self .__gender = "Male" def __getattr__ (self, attr ): return "Attribute not found" s = Student() >>> s.age'Attribute not found'
任何类,只需要定义一个__call__()方法,就可以直接对实例进行调用
通过callable()函数,我们就可以判断一个对象是否是“可调用”对象
1 2 3 4 5 6 7 8 9 10 11 12 13 class Student (): def __init__ (self ): self .__gender = "Male" def __call__ (self ): print ("Here I am!" ) s = Student() >>> s()Here I am! >>> callable (s)True
个人感觉本质上跟dict差不多,只不过Enum定义之后不可修改
Python3.4引入了enum标准库,之前的版本可以通过pip安装
有两种方法定义枚举:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from enum import EnumFruit = Enum('Fruit' , ('apple' , 'banana' , 'cherry' )) from enum import Enum, unique@unique class Fruit (Enum ): apple = 1 banana = 2 cherry = 3 f = Fruit() >>> Fruit.apple<Fruit.apple: 1 > >>> print (Fruit.cherry)Fruit.cherry >>> type (Fruit.banana)<enum 'Fruit' >
如果成员值允许相同(不用@unique),重复的会被当作别名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from enum import Enumclass Fruit (Enum ): apple = 1 banana = 2 another_apple = 1 >>> Fruit.apple<Fruit.apple: 1 > >>> Fruit.another_apple<Fruit.apple: 1 > >>> Fruit.apple == Fruit.another_appleTrue >>> Fruit(1 )<Fruit.apple: 1 > >>> Fruit["banana" ]<Fruit.banana: 2 > >>> Fruit.banana.name'banana' >>> Fruit.banana.value2
正常遍历不会获取别名,但是通过__members__(将名称映射到成员的有序字典)会获取全部成员。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from enum import Enumclass Fruit (Enum ): apple = 1 banana = 2 another_apple = 1 >>> for i in Fruit: print (i) Fruit.apple Fruit.banana >>> for i in Fruit.__members__.items(): print (i) ('apple' , <Fruit.apple: 1 >) ('banana' , <Fruit.banana: 2 >) ('another_apple' , <Fruit.apple: 1 >)
枚举的成员可以进行is或者==比较,不能进行大小比较
1 2 3 4 5 6 7 8 >>> Fruit.apple == Fruit.another_appleTrue >>> Fruit.apple is Fruit.bananaFalse >>> Fruit.apple < Fruit.bananaTraceback (most recent call last): File "<stdin>" , line 1 , in <module> TypeError: '<' not supported between instances of 'Fruit' and 'Fruit'
IntEnum是Enum的扩展,枚举的成员可以进行大小比较
1 2 3 4 5 6 7 8 9 10 11 from enum import IntEnumclass Fruit (IntEnum ): apple = 1 banana = 2 another_apple = 1 >>> Fruit.apple < Fruit.bananaTrue >>> Fruit.banana > 5 False
参考文章:Python的枚举类型
type()除了返回一个对象的类型,还能创建新的class。Python处理class也是调用type()来创建。
用法:type(class_name, (parent_class, ), dict(class_func_name = func))
1 2 3 4 5 6 7 8 9 10 11 12 class Student (object ): def __init__ (self, age=18 , gender="Male" ): self .age = age self .gender = gender def f (self, age=18 , gender="Male" ): self .age = age self .gender = gender Student = type ('Student' , (object ,), dict (__init__=f))
个人感觉没啥用,先把教程抄来丢这好了,方便以后翻。。。
metaclass是类的模板,所以在创建metaclass时必须继承type。
普通的list是没有add()方法的,可以看到这里通过metaclass模板添加了预设的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class ListMetaclass (type ): def __new__ (cls, name, bases, attrs ): attrs['add' ] = lambda self , value: self .append(value) return type .__new__(cls, name, bases, attrs) class MyList (list , metaclass=ListMetaclass): pass MyList = ListMetaclass('MyList' , (list ,), dict ()) >>> my_lst = MyList()>>> my_lst.add(1 )>>> my_lst[1 ]
个人觉得除了IDE debug,其它应该都没什么人用~
调试还是很有必要的,因为经常按下F5之后,帅不过三秒。。。
主要调试方法如下:
print()
assert
logging
pdb
IDE debug
assert 用法:assert cond, err_msg
如果cond不为True就会抛出AssertionError
命令行启动程序时可以用-O参数关闭assert
1 2 3 4 5 6 7 8 9 10 def divide (x, y ): x, y = int (x), int (y) assert y != 0 , "divide by zero!" print (x / y) >>> divide(8 ,0 )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> File "<stdin>" , line 3 , in divide AssertionError: divide by zero!
logging不会抛出错误,而且可以输出到文件
懒人如我是不可能另外写什么Test Case的~
使用Python自带的unittest模块
编写单元测试时,我们需要编写一个测试类,从unittest.TestCase继承
以test开头的方法就是测试方法,不以test开头的方法在测试的时候不会被执行
setUp()和tearDown()是单元测试中两个特殊的方法,这两个方法会分别在每调用一个测试方法的前后分别被执行。如果setUp()抛出错误,测试方法不会被执行。如果setUp()正常执行,无论测试方法是否抛出错误,tearDown()都一定会执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import unittestclass TestAbs (unittest.TestCase): def test_abs (self ): self .assertEqual(abs (-5 ), 5 ) self .assertEqual(abs (7 ), 7 ) def setUp (self ): print ("I run before testcase" ) def tearDown (self ): print ("I run after testcase" ) if __name__ == '__main__' : unittest.main()
输出如下:
1 2 3 4 5 6 7 I run before testcase I run after testcase . ---------------------------------------------------------------------- Ran 1 test in 0.004s OK
如果通过 python -i 运行 testcase,会在运行结束的时候抛出 SystemExit: False 错误。具体解释可以看python - Tests succeed, still get traceback - Stack Overflow
1 2 3 4 5 6 7 8 9 10 with open ('/path/to/file' , 'r' ) as f: print (f.read()) try : f = open ('/path/to/file' , 'r' ) print (f.read()) finally : if f: f.close()
open(file, mode='r', encoding=None, errors=None)
mode
r:read only(只读,默认)
w:write only(只写)
a:write & append(追加写入)
x:exclusive creation(新建写入,文件存在会报错)
b:binary mode(二进制模式)
t:text mode(文本模式,默认)
+:update(读写模式)
bt+这三个要跟在rwax后面用,例如rb、w+、r+b
读写建议使用r+模式,并且可以配合seek()和tell()
如果读取非UTF-8编码的文件,需要传入encoding参数,例如encoding='gbk'
errors='ignore'可以忽略编码错误
read():一次读取全部内容,返回str
read(size):每次最多读取size个字节
readline():每次读取一行
readlines():一次读取全部内容,按行返回list
write():传入入str
writelines():可以传入str或者str list,例如['apple', 'banana', 'cherry']是可以的,但是[11, 22, 33]就不行。writelines()不会对元素自动分割换行。
1 2 3 4 5 6 7 8 >>> from io import StringIO>>> f = StringIO()>>> f.write('hello' )5 >>> f.write('world!' )6 >>> f.getvalue()helloworld!
1 2 3 4 5 6 >>> from io import BytesIO>>> f = BytesIO()>>> f.write('哈哈' .encode('utf-8' ))6 >>> f.getvalue()b'\xe5\x93\x88\xe5\x93\x88'
函数
功能
os.name 操作系统类型
os.uname()
详细系统信息(Windows不提供)
os.environ
操作系统的环境变量
os.environ.get('key')
获取某个环境变量的值
os.path.abspath('.')
查看当前目录的绝对路径
os.path.join(dir1, dir2)
目录拼接
os.path.split(dir)
目录拆分(返回两部分,把最后一级拆出来)
os.mkdir()
创建目录
os.rmdir()
删除目录
os.path.splitext()
拿到文件扩展名('/path/to/file', '.txt')
os.rename(a, b)
重命名(a改成b)
os.remove(file)
删除文件
但是os模块不提供复制功能。。。
Function
Copies metadata
Copies permissions
Can use buffer
Destination may be directory
shutil.copy
No
Yes
No
Yes
shutil.copyfile
No
No
No
No
shutil.copy2
Yes
Yes
No
Yes
shutil.copyfileobj
No
No
Yes
No
用法:copyfile(src, dst)
Source: How do I copy a file in Python?
但是shutil似乎也不提供移动到回收站功能。。。
这个包可以跨平台移动到回收站,相当方便实用。
1 2 from send2trash import send2trashsend2trash("directory" )
Source: How can I move file into Recycle Bin?
函数
功能
json.dumps(obj)
返回一个JSON的str
json.dump(obj, fp)
把JSON写入文件
json.loads(s)
反序列化JSON
json.load(fp)
从文件反序列化JSON
个人不建议用pickle,因为根据官方文档,pickle模块并不安全,而且json太方便好用了。
函数
功能
pickle.dumps(obj)
把任意对象序列化成bytes
pickle.dump(obj, fp)
序列号对象并写入文件
pickle.loads(bytes)
反序列化对象
pickle.load(fp)
从文件反序列化对象
这个只能在Unix/Linux上面跑,不建议使用。
函数
功能
os.fork()
创建子进程(仅限Unix类系统)
os.getpid()
获取pid
由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去
from multiprocessing import Process
函数
功能
p = Process(target=func, args=[arg1])
创建Process实例
p.start()
启动实例
p.join()
等待实例运行结束(非守护进程的默认行为)
p.daemon = True
守护进程flag(守护进程在主进程结束时被终止)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from multiprocessing import Processimport osimport timedef child_process (name ): print (f"Started child process {name} , pid = {os.getpid()} " ) time.sleep(2 ) print ("child process done!" ) if __name__=='__main__' : print (f"Started parent process, pid = {os.getpid()} " ) p = Process(target=child_process, args=('child' ,)) p.start() p.join() print ("Finished!" )
输出如下:
1 2 3 4 Started parent process, pid = 14092 Started child process child, pid = 8108 child process done! Finished!
Source: What exactly is Python multiprocessing Module's .join() Method Doing?
如果要大量创建子进程,可以用进程池(Pool)。
from multiprocessing import Pool
函数
功能
Pool.apply
in-built apply
Pool.map
in-built map
Pool.apply_async
in-built apply
Pool.map_async
in-built map
Pool.map和Pool.apply将会给主程序上锁,直到所有进程完成。这样方便以特定的顺序获得结果。
相比之下,async将一次性提交所有进程,并在它们完成后立即取回结果。还有一个区别是,我们需要在apply_async()调用后使用get方法来获得已完成进程的 return值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import multiprocessing as mpdef cube (x ): return x**3 if __name__ == '__main__' : pool = mp.Pool(processes=4 ) results = [pool.apply(cube, args=(x,)) for x in range (1 ,7 )] print (results) pool = mp.Pool(processes=4 ) results = pool.map (cube, range (1 ,7 )) print (results) pool = mp.Pool(processes=4 ) results = [pool.apply_async(cube, args=(x,)) for x in range (1 ,7 )] output = [p.get() for p in results] print (output)
Source:
常见用法:subprocess.call(args, *, stdin=None, stdout=None, stderr=None, shell=False)
1 2 import subprocesssubprocess.call(['systeminfo' , '/?' ])
call()是Popen()的wrapper,两者用途比较类似。Popen()是异步执行,call()是同步执行。
1 2 3 returncode = call(*args, **kwargs) returncode = Popen(*args, **kwargs).wait()
Source: What's the difference between subprocess Popen and call (how can I use them)?
这个懒得看了,感觉也用不上,先丢个链接在这。
同一个机器上可以用multiprocessing的Queue或者Pipes模块处理。如果想把多进程分布到不同机器上,要用multiprocessing的managers模块处理。
Source:
_thread是低级模块,threading是高级模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 t = threading.Thread(target=func, name='thread_name' ) t.start() >>> threading.current_thread()<_MainThread(MainThread, started 1240 )> >>> threading.current_thread().name'MainThread' lock = threading.Lock() lock.acquire() lock.release()
GIL锁(Global Interpreter Lock)导致Python多线程只能用单核
ThreadLocal跟dict比较类似,不过ThreadLocal可以看作是全局变量,并且不同的线程只能管理属于自己的局部变量。
1 2 3 4 5 6 global bandname = band["thread_name" ]["name" ] name = band.name
这里给出一个在多线程使用ThreadLocal的例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import threading band = threading.local() def print_info (): name = band.name age = band.age role = band.role thread_name = threading.current_thread().name print (f"{[name, age, role]} in {thread_name} " ) def create_profile (name, age, role ): band.name = name band.age = age band.role = role print_info() t1 = threading.Thread(target=create_profile, args=("Yui" , 18 , "Guitarist" ), name="Thread_1" ) t2 = threading.Thread(target=create_profile, args=("Mio" , 18 , "Bassist" ), name="Thread_2" ) t1.start() t2.start() t1.join() t2.join()
输出如下:
1 2 ['Yui', 18, 'Guitarist'] in Thread_1 ['Mio', 18, 'Bassist'] in Thread_2
用Pool来批量创建子进程试试~
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import threadingimport multiprocessing as mpimport timeprofile = [ ["Yui" , 18 , "Guitarist" ], ["Mio" , 18 , "Bassist" ], ["Ritsu" , 18 , "Drummer" ], ["Tsumugi " , 18 , "Keyboardist" ], ["Azusa " , 17 , "Guitarist" ] ] band = threading.local() def print_info (): name = band.name age = band.age role = band.role thread_name = mp.current_process().name print (f"{[name, age, role]} in {thread_name} " ) time.sleep(1 ) def create_profile (name, age, role ): band.name = name band.age = age band.role = role print_info() if __name__ == '__main__' : pool = mp.Pool(processes=5 ) print ([w.name for w in pool._pool]) results = [pool.apply(create_profile, args=(profile[x][0 ], profile[x][1 ], profile[x][2 ])) for x in range (len (profile))]
输出如下:
1 2 3 4 5 6 ['SpawnPoolWorker-1', 'SpawnPoolWorker-2', 'SpawnPoolWorker-3', 'SpawnPoolWorker-4', 'SpawnPoolWorker-5'] ['Yui', 18, 'Guitarist'] in SpawnPoolWorker-1 ['Mio', 18, 'Bassist'] in SpawnPoolWorker-4 ['Ritsu', 18, 'Drummer'] in SpawnPoolWorker-2 ['Tsumugi ', 18, 'Keyboardist'] in SpawnPoolWorker-3 ['Azusa ', 17, 'Guitarist'] in SpawnPoolWorker-5
这里看到一个流传广泛的讲解,感觉确实生动形象,挺有意思的,就原封不动贴来这里。具体出处已经不可考。
老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
#1 老张把水壶放到火上,立等水开。(同步阻塞);立等就是阻塞了老张去干别的事,老张得一直主动的看着水开没,这就是同步。
#2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞);老张去看电视了,这就是非阻塞了,但是老张还是得关注着水开没,这也就是同步了。
#3 老张把响水壶放到火上,立等水开。(异步阻塞);立等就是阻塞了老张去干别的事,但是老张不用时刻关注水开没,因为水开了,响水壶会提醒他,这就是异步了
#4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞);老张去看电视了,这就是非阻塞了,而且,等水开了,响水壶会提醒他,这就是异步了。
所谓同步异步,只是对于水壶而言。普通水壶,同步;响水壶,异步。对应的也就是消息通信机制。虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。立等的老张,阻塞;对应的也就是程序等待结果时的状态。看电视的老张,非阻塞。情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
asyncio是Python 3.4引入的标准库。
基于yield from的协程的支持在Python 3.8被弃用,并会在Python 3.10中移除。所以老教程可以不用看了,以后都用async def。
下面是一个同步阻塞的求和程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def sum (n ): print (f"Calculating sum({n} )..." ) val = 1 for i in range (1 , n+1 ): val += i print (f"sum({n} ) done!" ) return val def main (): res_4 = sum (10000000 ) res_1 = sum (50000 ) res_2 = sum (100000 ) res_3 = sum (1000000 ) return res_1, res_2, res_3, res_4 if __name__ == '__main__' : r1, r2, r3, r4 = main() print (r1)
执行顺序如下所示。注意到 sum(10000000) 会阻塞很久,后面的任务全部只能排队等候。
1 2 3 4 5 6 7 8 Calculating sum(10000000)... sum(10000000) done! Calculating sum(50000)... sum(50000) done! Calculating sum(100000)... sum(100000) done! Calculating sum(1000000)... sum(1000000) done!
接下来把求和程序用asyncio改造成异步非阻塞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioasync def sum (n ): print (f"Calculating sum({n} )..." ) val = 1 for i in range (1 , n+1 ): val += i if i % 50000 == 0 : await asyncio.sleep(0.0001 ) print (f"sum({n} ) done!" ) return val async def main (): res_1 = loop.create_task(sum (10000000 )) res_2 = loop.create_task(sum (50000 )) res_3 = loop.create_task(sum (100000 )) res_4 = loop.create_task(sum (1000000 )) await asyncio.wait([res_1, res_2, res_3, res_4]) return res_1, res_2, res_3, res_4 if __name__ == '__main__' : loop = asyncio.get_event_loop() r1, r2, r3, r4 = loop.run_until_complete(main()) print (r1.result()) loop.close()
执行顺序如下所示。虽然 sum(10000000) 还是最先执行,但是程序并没有阻塞,而是先把容易计算的项目跑完了,最后才输出的 sum(10000000) 结果。
1 2 3 4 5 6 7 8 Calculating sum(10000000)... Calculating sum(50000)... Calculating sum(100000)... Calculating sum(1000000)... sum(50000) done! sum(100000) done! sum(1000000) done! sum(10000000) done!
但是在上面这个例子,使用异步比同步要慢。因为求和属于CPU密集型(CPU-bound),异步需要额外的开销切换context,最后适得其反。对于IO密集型(I/O bound),使用异步会快很多,不用浪费时间在等待硬盘读写和网络请求上面。
Source: Asyncio - Asynchronous programming with coroutines
上面说到异步对IO密集型任务比较有效,所以aiohttp就比较实用了。aiohttp是基于asyncio的第三方包,需要用pip安装。
我研究了一会儿,终于糊出来一个能跑通的demo,这段程序是向reddit用异步方式发10次GET请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import asyncioimport aiohttpimport timedef timer (func ): def wrapper (): before = time.time() func() print ("Function took:" , time.time() - before, "seconds" ) return wrapper async def fetch (session, cnt ): async with session.get("https://www.reddit.com/" ) as r: res = await r.text() print (f"{cnt} Done!" ) async def request (): async with aiohttp.ClientSession() as session: task_lst = [] for i in range (10 ): t = fetch(session, i + 1 ) task = asyncio.create_task(t) task_lst.append(task) await asyncio.gather(*task_lst) @timer def main (): loop = asyncio.get_event_loop() loop.run_until_complete(request()) >>> main()3 Done!9 Done!10 Done!2 Done!5 Done!4 Done!6 Done!8 Done!1 Done!7 Done!Function took: 3.803086519241333 seconds
接下来我又用传统的requests写了功能一样的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import requestsimport timedef timer (func ): def wrapper (): before = time.time() func() print ("Function took:" , time.time() - before, "seconds" ) return wrapper def fetch (session, cnt ): r = session.get("https://www.reddit.com/" ) res = r.text print (f"{cnt} Done!" ) @timer def req (): session = requests.Session() for i in range (10 ): fetch(session, i + 1 ) >>> req()1 Done!2 Done!3 Done!4 Done!5 Done!6 Done!7 Done!8 Done!9 Done!10 Done!Function took: 23.327841997146606 seconds
可以看到这种情况下,同步阻塞的requests比异步非阻塞的aiohttp要慢一个数量级。在需要发送一大堆请求的时候,aiohttp的威力确实不容小觑。
当然requests还是可以垂死挣扎一下,搭配threading模块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import requestsimport threadingimport timedef timer (func ): def wrapper (): before = time.time() func() print ("Function took:" , time.time() - before, "seconds" ) return wrapper def fetch (session, cnt ): r = session.get("https://www.reddit.com/" ) res = r.text print (f"{cnt} Done!" ) @timer def req (): session = requests.Session() threads = [] for i in range (10 ): t = threading.Thread(target=fetch, name=f"Thread_{i+1 } " , args=(session, i + 1 )) threads.append(t) for t in threads: t.start() for t in threads: t.join() >>> req()5 Done!4 Done!7 Done!9 Done!10 Done!3 Done!2 Done!1 Done!8 Done!6 Done!Function took: 4.179023027420044 seconds
居然跟使用aiohttp的时间差不多,看来zhaouv说的还是比较有道理,python的话有GIL,直接开十个线程去请求,效率和资源占用应该会和异步非常接近。
virtualenv是python的虚拟运行环境,可以创建独立的运行环境,从而装上不同版本的包。在虚拟环境中,按正常方法用pip安装包即可。环境用完之后直接删除就行。
virtualenv不是自带包,需要用pip安装。
1 2 3 4 5 6 7 8 9 10 # 创建名为 venv 的虚拟环境(默认纯净的Python环境,无第三方包) virtualenv venv # 进入 / 退出虚拟环境(Windows) venv\Scripts\activate venv\Scripts\deactivate # 进入 / 退出虚拟环境(Linux / Mac) source venv/bin/activate source venv/bin/deactivate
Source: Pipenv & 虚拟环境 — The Hitchhiker's Guide to Python
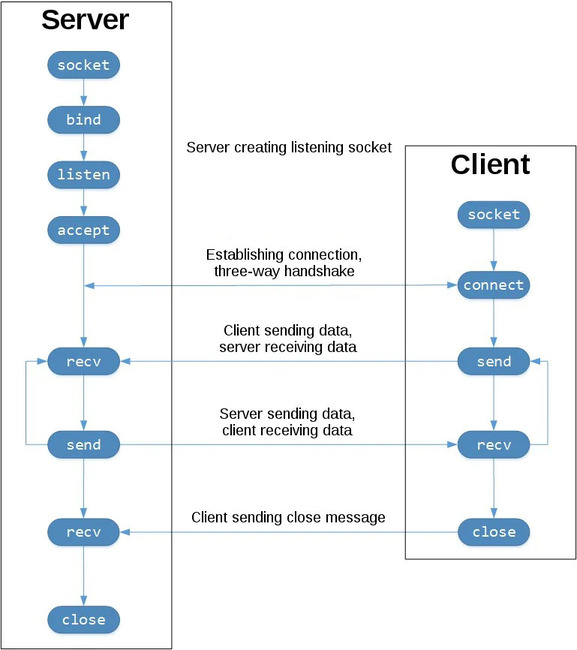
socket 可以建立TCP和UDP连接,在server和client之间方便的通信。
下面是socket常用的一些方法。
socket()
创建 socket 对象
bind()
把 socket 跟地址绑定
listen()
让 socket 对象开始监听
accept()
等待入站连接(阻塞)
connect()
连接到指定地址的 socket
connect_ex()
connect(), 但 C-level 错误不抛出异常
send()
发送数据(需要手动检查是否全部发送)
sendall()
send(),直到发完数据或者出错
recv()
接收数据
close()
关闭 socket
这里抄来一个socket最小实例,有server和client两段代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import socketHOST = "127.0.0.1" PORT = 23456 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() print ("Server listening for incoming connection..." ) conn, addr = s.accept() with conn: print (f"Connected by {addr} " ) while True : data = conn.recv(1024 ) if not data: break conn.sendall(data) import socketHOST = "127.0.0.1" PORT = 23456 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect((HOST, PORT)) s.sendall(b'Hello, world' ) data = s.recv(1024 ) print ('Received' , repr (data))
先运行server.py,然后运行client.py,可以得到下面输出。
1 2 3 4 5 6 # server.py Server listening for incoming connection... Connected by ('127.0.0.1', 8018) # client.py Received b'Hello, world'
启动server.py之后,可以通过netstat命令看到连接情况。
1 2 >netstat -an | findstr "23456" TCP 127.0.0.1:23456 0.0.0.0:0 LISTENING
TODO:用socket实现一个http server(懒)
Source:
乘法运算和可变参数特别常见,略过不表。
1 2 3 4 5 6 >>> [1, 2, 3] * 2 [1, 2, 3, 1, 2, 3] >>> [[1, 2, 3]] * 2 [[1, 2, 3], [1, 2, 3]] >>>
对于list/tuple,在前面加上*即可展开
1 2 3 4 5 6 7 8 9 10 11 12 13 def add (a,b,c,d=0 ,e=0 ): print (a+b+c+d+e) x = [1 ,2 ,3 ] y = (4 ,5 ) >>> add(*x)9 >>> add(*x, *y)15
基本上常用又不熟悉的就这些了。当然Python还有五花八门的各种标准库,也不可能一个个去看,用到再说好了。
遇事不决翻文档:Python 标准库